
Label Encoding & One-Hot Encoding
label encoding의 경우 'object'타입을 따로 빼서 적용하는 방법이 있다.
- 먼저 'object' 타입들을 따로 뺀다.
df1_obj = df1.select_dtypes("object")- sklearn의 LabelEncoder를 import한다. 그 다음 fit_transform()을 통해서 object 형태를 숫자 형태로 바꿔준다.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df1['cust_clas_itg_cd'] = le.fit_transform(df1_obj['col1'])- One-Hot Encoding은 다음과 같이 하면 된다. get_dummies로 원하는 열들을 바꾸며 drop_first=True로 해서 one-hot encoding결과에서 열 하나는 버리도록 한다.
df1 = pd.get_dummies(data=df1, columns=['col1', 'col2', 'col3'], drop_first=True)
df1x,y 분리
- train_test_split()을 통해서 간단하게 구현이 가능하다.
x = df1.drop(target, axis=1)
y = df1[target]
y = pd.DataFrame(y)
y['trm_yn_Y'].value_counts(normalize=True).plot(kind='bar')
from sklearn.model_selection import train_test_split
x_train, x_test, y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=1,shuffle=True)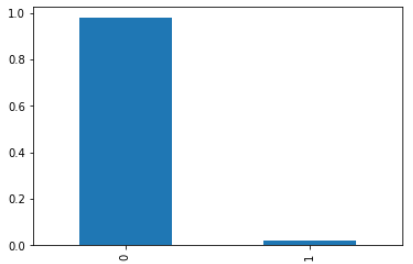
그래프를 보면 label이 불균형하다. 대부분 0으로 예측할 것으로 보인다.
데이터 정규분포화, 표준화
- 방식은 Minmax Scaler, Standard Scaler 방식 2가지가 있다.
- StandardScaler
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# StandardScaler 적용
x_train_n = scaler.fit_transform(x_train)
x_test_n = scaler.transform(x_test)- MinmaxScaler
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
'Certificate > AICE' 카테고리의 다른 글
| AICE Associate - ML 모델링 (0) | 2023.04.20 |
|---|---|
| AICE Associate - 데이터 전처리1(데이터 확인 및 결측치 처리) (0) | 2023.04.11 |
| AICE Associate - 라이브러리 설치 및 import (0) | 2023.04.10 |